
Semantic Complexity Gap
Recently I came across an interesting phenomenon concerning the CLIP text encoder embedding space: I have discovered yet another gap in the CLIP embedding space - the semantic complexity gap. I played around with embeddings of words and sentences when I noticed an interesting pattern: atomic words occupy the same cluster with single-concept sentences while multi-concept sentences form a distinct cluster.
Single- vs Multi-Concept Sentences
By single-concept sentences I mean sentences that bring together related concepts that have been likely in the training data. By multi-concept sentences I mean sentences that unify unrelated concepts that are unlikely in the training data.
A list of single-concept sentences:
- Love and friendship go hand in hand just like best friends.
- The sun sets beautifully over the ocean, creating a perfect end to the day.
- Music and art often inspire each other, leading to creative masterpieces.
- Cooking is an art that brings people together around the dinner table.
A list of multi-concept sentences:
- The cat danced with the moon while eating chocolate.
- A guitar floated across the ocean, singing about a dragon.
- The computer played a symphony for a mountain of pizza.
- A sunflower rode a bicycle through a jungle of clouds.
Experimental Setup
- Embed 10,000 most common English words (atomic concepts)
- Embed curated list of multi-concept sentences (unrelated concepts)
- Embed curated list of single-concept sentences (related concepts)
- Create 2D projection of atomic words + multi-concept sentences
- Create 2D projection of atomic words + single-concept sentences
2D projection of Atomic words + Single-concept sentences
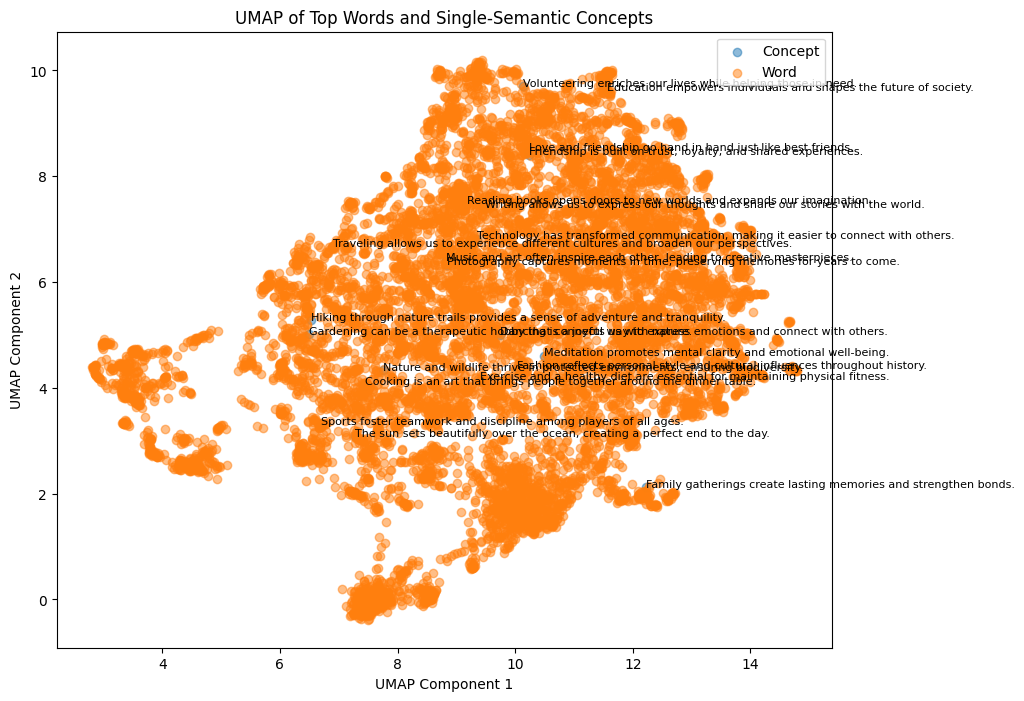
The single-concept sentences nicely spread out the big cluster of atomic words (occupying the same latent sub-space).
2D projection of Atomic words + Multi-concept sentences
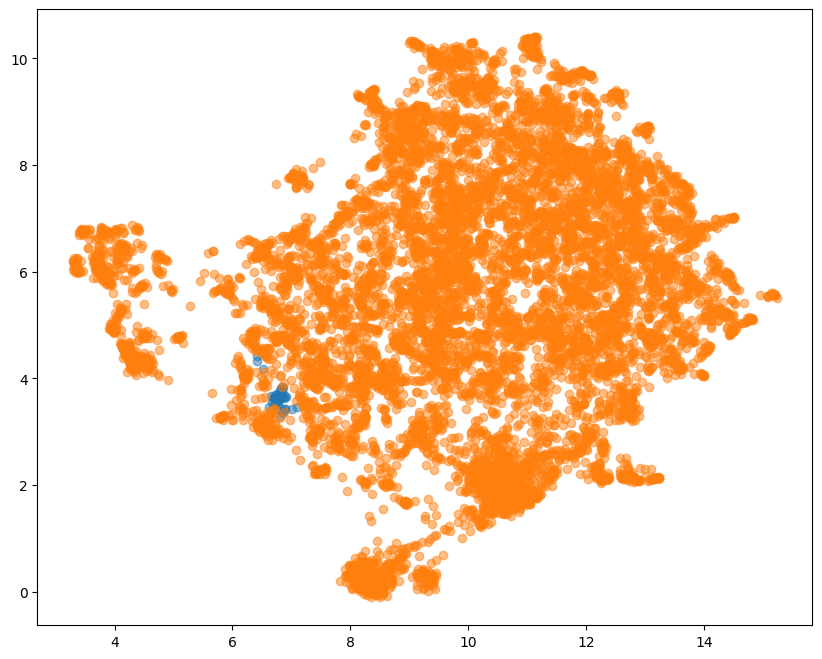
The multi-concept sentences on the other hand form a tight seperate cluster that does not spread out around the atomic words.
How does this relate to the Linear Hypothesis?
The distribution of the single-concept sentences is nicely explained by the linear hypothesis, which states that neural networks learn to organize semantic concepts in a way that makes them linearly separable and that meaningful semantic transformations can often be represented as linear operations in the embedding space.
The distribution of the multi-concept (unrelated) sentences may hint at the limits of the linear hypothesis, namely that it does not hold for out-of-distribution samples.
Show me the code
Here is my code (Jupyter Notebook): https://github.com/SeanPedersen/semantic-complexity-gap/blob/main/CLIP_Concept_Gap.ipynb
Open Questions
- Is this just a random artifact or a novel phenomenon? (I did not put much time and rigor into this - so I am curious if this is reality)
- Does this semantic complexity gap between related and unrelated concepts also occur for ImageNet classifiers (e.g. image of cat and dog vs image of cat and airplane?